Implementing H-Net
H-Net Paper Quick (and probably incorrect) Implementation
[Link to the full code]
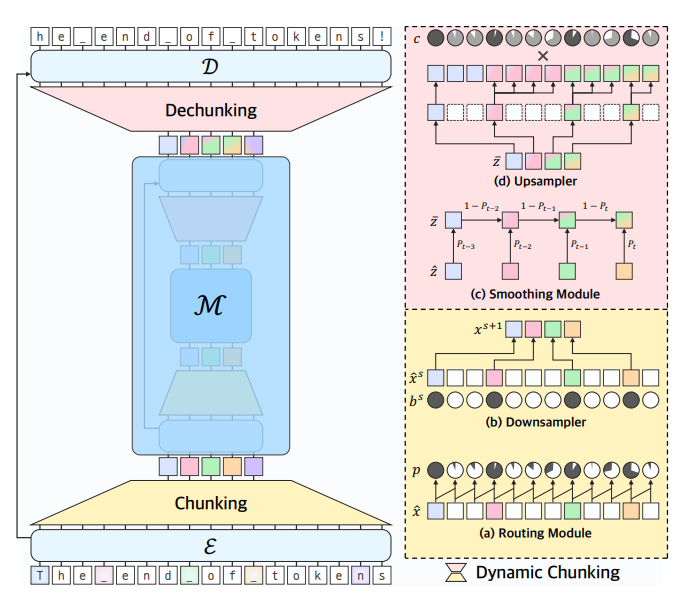
Architecture Overview
The H-Net architecture consists of encoder, main, and decoder networks joined together by chunking and dechunking modules.
Encoder
The encoder is a regular sequence model (e.g. transformer, mamba) that processes raw bytes (vocab size 256). Instead of a projection layer at the end, however, the hidden states are sent directly to the chunking module.
Dynamic Chunking
Routing Module
The routing module compares the encoded bytes to one another using cosine similarity to produce probabilities for chunk boundaries. When the representation of one byte is significantly different from the previous, there is a higher probability of a boundary between chunks.
Downsampler
In the downsampler, the boundary probabilities are cut off at $p=0.5$ to be either $1$ or $0$. Then the hidden vectors for the boundary tokens ($p=1$) are simply selected concatenated together into a condensed tensor to be sent to the main network.
Chunking Module Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class Chunking(nn.Module):
"""Chunking module, includes boundary calculation and selection"""
def __init__(self, d_model: int):
super().__init__()
self.d_model = d_model
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
def forward(self, x: torch.Tensor):
B, T, C = x.size()
# calculate q and k for all tokens
q = self.wq(x)
k = self.wk(x)
# initialize an empty probability tensor
p = torch.empty(B, T)
# prefill first column to 1 because it must be a boundary
p[:, 0] = 1
# loop through all tokens and calculate similarity, un-similar tokens have higher boundary probability
for b in range(B):
for t in range(1, T):
p[b, t] = 0.5 * (1 - (torch.dot(q[b, t], k[b, t-1])) / (torch.linalg.norm(q[b, t]) * torch.linalg.norm(k[b, t-1])))
# boundary cutoff
b = torch.where(p > 0.5, 1, 0)
# make a tensor the size of the longest chunked sequence and zero out the rest for other sequences
longest = b.sum(1).max().int().item()
out = torch.zeros(B, longest, C)
# put in the boundary tokens
for batch in range(B):
for time in range(T):
if b[batch, time].int().item() == 1:
out[batch, b[batch][:time].sum().int().item()] = x[batch, time]
return out, p , b
Main Network
The main network operates only on boundary-marked vectors, maintaining a low input sequence length. Because of this, the authors make use of a transformer rather than the mamba blocks used in the encoder and decoder for their linear computation cost. During inference, the main network is only stepped if the routing module marks the encoder output as a boundary. Otherwise, the chunks are sent straight to dechunking and the decoder.
Dechunking
Smoothing Module
The smoothing module allows information from different chunks to be used in the calculation of gradients for each chunk by applying a moving average to each chunk depending on its boundary probability.
Upsampling
The upsampler essentially duplicates each boundary vector to fill up the length of its chunk. The authors use a Straight Through Estimator to pretend that, in the backward pass, each of the upsampled vectors was weighted by its confidence $c_t$, which rewards high boundary probabilities in boundary vectors and punishes high boundary probabilities for non-boundary vectors, incentivizing the model to be confident in its boundary predictions.
Dechunking Module Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class Dechunking(nn.Module):
"""Dechunking module, includes smoothing and upsampling"""
def __init__(self):
super().__init__()
def forward(self, z_hat: torch.Tensor, p: torch.Tensor, b: torch.Tensor):
B, T, C = z_hat.size()
# smoothing
z_bar = torch.empty_like(z_hat)
# moving average for gradients
for batch in range(B):
for t in range(1, T):
z_bar[batch, t] = p[batch, t] * z_hat[batch, t] + (1- p[batch, t]) * z_bar[batch, t-1]
# upsampler
# confidence scores per input token
c = p ** b * (1 - p) ** (1 - b)
# make an empty tensor to store expanded tokens
z_tilde = torch.empty(B, p.size(1), C)
# copy each boundary tensor until next boundary index
for batch in range(B):
for t in range(p.size(1)):
z_tilde[batch, t] = z_hat[batch, b[batch][:t].sum().int().item() - 1]
# pretend to weight by confidence for backprop
return ste(c).unsqueeze(2) * z_tilde
Decoder
The decoder is another sequence model that processes the upsampled chunks either from the encoder or main network, outputting a probability distribution for the next byte in the sequence to be sent back to the beginning of the network.
Residuals and Normalization
Although not much time is spent discussing residuals in the paper, they play a large role in the architecture. The outputs from each encoder are sent through a projection layer and added to the result of the dechunking module to allow the model to differentiate between tokens and promote gradient flow. RMSNorm is also added after the encoder, main, and decoder networks.
H-Net Model PyTorch Implementation
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
import torch
import torch.nn as nn
from mamba_ssm import Mamba2
torch.set_default_device("cuda")
torch.set_float32_matmul_precision("high")
# ----------------- Helper functions ----------------------
class STE(torch.autograd.Function):
@staticmethod
def forward(ctx, xs):
return torch.ones_like(xs).float()
@staticmethod
def backward(ctx, grad_output):
return grad_output
def ste(x):
return STE.apply(x)
# --------------------- Modules ---------------------------
class Chunking(nn.Module):
"""Chunking module, includes boundary calculation and selection"""
def __init__(self, d_model: int):
super().__init__()
self.d_model = d_model
self.wq = nn.Linear(d_model, d_model)
self.wk = nn.Linear(d_model, d_model)
def forward(self, x: torch.Tensor):
B, T, C = x.size()
# calculate q and k for all tokens
# could probably use a cache here but i've spent too much time implementing this already
q = self.wq(x)
k = self.wk(x)
# initialize an empty probability tensor
p = torch.empty(B, T)
# prefill first column to 1 because it must be a boundary
p[:, 0] = 1
# loop through all tokens and calculate similarity, un-similar tokens have higher boundary probability
for b in range(B):
for t in range(1, T):
p[b, t] = 0.5 * (1 - (torch.dot(q[b, t], k[b, t-1])) / (torch.linalg.norm(q[b, t]) * torch.linalg.norm(k[b, t-1])))
# boundary cutoff
b = torch.where(p > 0.5, 1, 0)
# make a tensor the size of the longest chunked sequence and zero out the rest for other sequences
longest = b.sum(1).max().int().item()
out = torch.zeros(B, longest, C)
# put in the boundary tokens
for batch in range(B):
for time in range(T):
if b[batch, time].int().item() == 1:
out[batch, b[batch][:time].sum().int().item()] = x[batch, time]
return out, p , b
class Dechunking(nn.Module):
"""Dechunking module, includes smoothing and upsampling"""
def __init__(self):
super().__init__()
def forward(self, z_hat: torch.Tensor, p: torch.Tensor, b: torch.Tensor):
B, T, C = z_hat.size()
# smoothing
z_bar = torch.empty_like(z_hat)
# moving average for gradients
for batch in range(B):
for t in range(1, T):
z_bar[batch, t] = p[batch, t] * z_hat[batch, t] + (1- p[batch, t]) * z_bar[batch, t-1]
# upsampler
# confidence scores per input token
c = p ** b * (1 - p) ** (1 - b)
# make an empty tensor to store expanded tokens
z_tilde = torch.empty(B, p.size(1), C)
# copy each boundary tensor until next boundary index
for batch in range(B):
for t in range(p.size(1)):
z_tilde[batch, t] = z_hat[batch, b[batch][:t].sum().int().item() - 1]
# pretend to weight by confidence for backprop
return ste(c).unsqueeze(2) * z_tilde
class MambaModel(nn.Module):
"""Just a wrapper around the Mamba2 block to add layers"""
def __init__(self, n_layers: int = 12, d_model: int = 768, headdim: int = 4, d_state: int = 4, d_conv: int = 2, expand: int = 2):
super().__init__()
self.d_model = d_model
self.headdim = headdim
self.d_state = d_state
self.d_conv = d_conv
self.expand = expand
self.n_layers = n_layers
self.layer_stack = nn.ModuleList(
Mamba2(
d_model=d_model,
headdim=headdim,
d_state=d_state,
d_conv=d_conv,
expand=expand,
) for _ in range(n_layers)
)
def forward(self, x: torch.Tensor):
for l in self.layer_stack:
x = l(x)
return x
class HNet(nn.Module):
def __init__(self, encoder_layers: int = 2, main_layers: int = 4, decoder_layers: int = 2, d_model: int = 64, headdim: int = 16, d_state: int = 16, d_conv: int = 4, expand: int = 2):
super().__init__()
# mamba blocks
self.d_model = d_model
self.headdim = headdim
self.d_state = d_state
self.d_conv = d_conv
self.expand = expand
# byte embedding
self.emb = nn.Embedding(256, d_model)
self.residual_proj = nn.Linear(d_model, d_model)
# encoder sequence model (using mamba)
self.encoder = MambaModel(
n_layers=encoder_layers,
d_model=d_model,
d_state=d_state,
d_conv=d_conv,
expand=expand,
)
# post-encoder normalization
self.encodernorm = nn.RMSNorm(d_model)
# dynamic chunking module from before
self.chunking = Chunking(d_model)
# main model (would normally be a transformer)
self.main = MambaModel(
n_layers=main_layers,
d_model=d_model,
d_state=d_state,
d_conv=d_conv,
expand=expand,
)
# post-main normalization
self.mainnorm = nn.RMSNorm(d_model)
# dechunking from before
self.dechunking = Dechunking()
# decoder mamba model
self.decoder = MambaModel(
n_layers=decoder_layers,
d_model=d_model,
d_state=d_state,
d_conv=d_conv,
expand=expand,
)
# post-decoder normalization
self.decodernorm = nn.RMSNorm(d_model)
# project decoder hidden state to bytes again
self.decoder_proj = nn.Linear(d_model, 256)
def forward(self, x_bytes: torch.Tensor):
# encode the bytes of the input to vectors
x = self.emb(x_bytes)
# run input through the encoder
encoder_out = self.encodernorm(self.encoder(x))
# calculate boundary probabilities and chunk
chunking_out, p, b = self.chunking(encoder_out)
# run main network on the chunked bytes
main_out = self.mainnorm(self.main(chunking_out))
# dechunk the output from main and add residuals from encoder
dechunking_out = self.dechunking(main_out, p, b) + self.residual_proj(encoder_out)
# decode the upsampled outputs back to bytes
decoder_out = self.decodernorm(self.decoder(dechunking_out))
# return logits, probs, and boundaries for loss
logits = self.decoder_proj(decoder_out)
return logits, p, b
def inference(self, x_bytes: torch.Tensor):
# more or less the same as training
x = self.emb(x_bytes)
encoder_out = self.encodernorm(self.encoder(x))
chunking_out, p, b = self.chunking(encoder_out)
# only step main if boundary
if b[0][-1] == 1:
chunking_out = self.mainnorm(self.main(chunking_out))
dechunking_out = self.dechunking(chunking_out, p, b) + self.residual_proj(encoder_out)
decoder_out = self.decodernorm(self.decoder(dechunking_out))
logits = self.decoder_proj(decoder_out)
return logits
My Opinions on the Paper
This paper presents multiple useful ideas, but ultimately has some major drawbacks. The use of dynamic chunking to replace tokenization could be very helpful, especially for larger models with broad multilingual and coding capabilities, although tokenization might still be a more effective method for smaller, limited-capability models.
It almost feels as though the paper is trying to tackle too many concepts at once, with the authors simultaneously focued on better tokenization, hierarchical learning, and inference optimization with speculative decoding. I think it is best to focus on the ideas presented in the context of speculative decoding, as it makes the concepts presented feel more natural to the overarching premise. I orignially tried to understand the paper thinking that the alternative to tokenization was the sole purpose of the work, which made the architecture as a whole feel slightly unnecessary and unintuitive.
Possibly the biggest drawback to the paper is computational efficiency. No amount of flop-matching on loss plots can cover up an inefficient architecture. The only x-axis that matters to me is time. If your work doesn’t take advantage of the strengths of existing GPUs, it isn’t likely to succeed. I think the contributions of this paper are important, but the H-Net architecture itself isn’t going to be widely used without more hardware-aware optimization. I don’t like the fact that the constraints of GPUs have made so many solid ideas unrealistic in practice, but this is the reality we have to work with.
With that said, I am optimistic about the idea of learnable tokenization, and the idea of hierarchical models seems interesting. While this particular architecture might not be perfect, some of its concepts will likely be useful in future research as a step in a new and possibly successful direction.
Paper Citation:
1
2
3
4
5
6
@article{hnet,
title={Dynamic Chunking for End-to-End Hierarchical Sequence Modeling},
author={Hwang, Sukjun and Wang, Brandon and Gu, Albert},
journal={arXiv preprint arXiv:2507.07955},
year={2025}
}